The Quest for Raw Feeds in the Live Framework
Ever since I started playing with Live Framework, I’ve wanted to import Atom feeds from external sources such as blogs, Twitter, and various Google Data APIs. Surprisingly, as we will see later, this is not easy.
I am most interested in annotating Twitter feeds and synchronizing those annotations between multiple devices, apps, and users. Why would I want to do this? Because this can address a number of limitations with Twitter and existing Twitter clients:
- Read/unread status isn’t shared between apps and devices
- Groups and saved searches aren’t synchronized
- No third option between public and protected accounts
- Favorites are public (no private or semi-private favorites)
- Availability issues due to fail whales, being offline, etc.
- You must be online to tweet, favorite, and follow
- You don’t own your data, Twitter does
- No good path for migrating from centralized tweets (twitter.com) to a decentralized, federated model
- Twitter’s crossdomain.xml doesn’t support direct access by Silverlight and Flash apps
That last point on crossdomain.xml is particularly frustrating since you would think that between Silverlight 3 Out-of-Browser and Live Framework it would be straight-forward to build a reasonable competitor to TweetDeck, Twhirl, or Seesmic Desktop (Adobe AIR’s killer apps), but that is not the case.
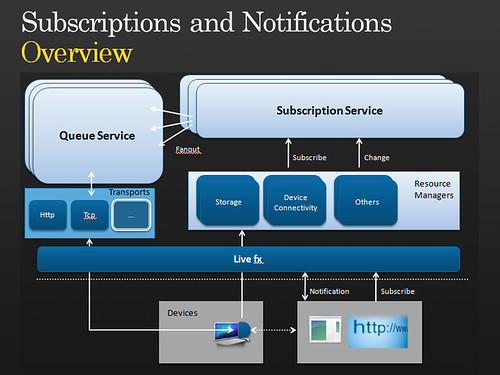
Atom in the Live Framework
Before discussing the issues with importing Atom feeds, it is useful to consider how the Live Framework uses Atom. As you may know, Atom is the Live Framework’s native infoset. These Atom feeds can be accessed using other representations such as RSS, JSON, and POX, but the abstract infoset is fundamentally Atom, supplemented by AtomPub for CRUD and FeedSync for sync.
Live Framework then layers a resource model on top of Atom. This resource model adds schemas for data such as News, Contacts, MeshDevices, MeshObjects, and more. These schemas can be discovered by using the OPTIONS HTTP verb or by reading the Resource Model documentation. As you can see from the documentation, all schemas are based on the abstract Resource schema which includes a number of general-purpose Atom properties as well as Mesh-specific properties such as Triggers.
What’s wrong with a little schema?
The resource type closest to a raw Atom entry is the DataEntryResource. Conveniently, it supports arbitrary element and attribute extensions, so it looks like you ought to be able to shove any arbitrary Atom entry into a DataEntry.
It turns out that while DataEntry’s schema provides a home for every possible Atom data element, in practice some of the elements are reserved or have special behavior. Further, this behavior is inconsistent between the local LOE and the cloud LOE, although the inconsistency can be used to hack around some of the limitations, highlighting the power of the back door endpoints used by the Live Framework Client.
Reserved elements
The Live Framework doesn’t let you store your own arbitrary data in the following elements of an Atom entry:
- id
- published
- updated
- content
If you attempt to provide your own values for these elements, they will be overwritten with auto-generated values by the cloud Live Operating Environment.
The <id> element will always be set to a random GUID such as:
<id>urn:uuid:05950d5f-4815-3269-c6a6-e4620256033e</id>
The <published> and <updated> elements will always be set to the cloud LOE’s DateTime.UtcNow. Actually, this isn’t true for <published> on the local LOE but we’ll get to that later.
Forcing <published> and <updated> to DateTime.UtcNow causes problems when bulk importing entries. All of the entries will share the same time, making sorting impossible. This is particularly problematic because currently you can’t sort on custom elements, so even if you store the original <published> and <updated> elements under different names, you’re out of luck when it comes to sorting and filtering.
The <content> element is used as a grab bag for all sorts of LiveFX-specific content:
<content type="application/xml">
<DataEntryContent xmlns:i="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://user.windows.net" />
</content>
<content> is also where you will see Triggers if any have been attached to the resource.
Clobbering the <content> element is a big problem for importing blog feeds because this is where the blog post body content lives.
On a side note, it appears that the Live Framework only supports <title> and <subtitle> elements where type=“text”, but I could be wrong.
Additional elements
Live Framework preserves the original <author> element, but adds a second <author> element with the <name>, <uri>, and <email> of the LiveID user account that imported the entry. The Live Framework author element appears before any external author elements. It is perfectly valid for Atom entries to have more than one author, but this is something to watch out for if your app assumes only one author per entry or if author information has app-level significance.
I haven’t tried importing entries with pre-existing <category> or <link> elements, but I assume they would successfully import and be supplemented by additional LiveFX-specific <category> and <link> elements.
Local LOE differences
After learning how the cloud LOE behaves, I tried importing Atom feeds from Twitter into the local LOE. Unlike the cloud LOE, the local LOE preserved the original <published> element. However, the <updated> element was again set to DateTime.UtcNow, just like on the cloud LOE. At least I can now use LiveFX’s support for sorting, filtering, and paging imported Twitter feeds by the <published> date.
After successfully preserving the <published> element by using the local LOE, I checked the same feed on the cloud LOE after it synchronized. Amazingly, the cloud LOE now showed the correct original <published> date! “Aha,” I thought, “I should be able to make the cloud LOE accept the original <published> date by talking to it using FeedSync instead of AtomPub.”
Unfortunately, accessing the cloud LOE DataFeed’s Sync feed using FeedSync did not preserve the original <published> date. Very interesting! Then how did the local LOE successfully sync the original <published> dates to the cloud LOE?
The parallel universe of Windows Live Core
“This is your last chance. After this, there is no turning back. You take the blue pill - the story ends, you wake up in your bed and believe whatever you want to believe. You take the red pill - you stay in Wonderland and I show you how deep the rabbit-hole goes.” – Morpheus, The Matrix
Ok, perhaps I’m being overly dramatic. :-) But seriously, what you know as MeshObjects, ApplicationInstances, and so on are actually CoreObjects living in the grittier, undocumented world of the Windows Live Core (WLC). The local and cloud LOEs are like the Matrix, hiding the WLC from you and letting you believe that the shiny world of Live Framework is all there is.
There are three main endpoints in WLC:
- accounts.developer.mesh-ctp.com
- storage.developer.mesh-ctp.com
- enclosure.developer.mesh-ctp.com
Accounts is responsible for managing the 3 types of identity in the mesh: users, devices, and apps. Accounts is also responsible for ApplicationClaims (mapping apps to users) and DeviceClaims (mapping devices to users). Storage is where CoreObjects live. Enclosure is where CoreObject media resources live.
The Live Framework Client synchronizes with the cloud using storage.developer.mesh-ctp.com, not user-ctp.windows.net, and instead of hitting the DataFeed’s /Sync URI, it hits the /Sse URI. SSE is Simple Sharing Extensions, the old name for FeedSync.
storage.developer.mesh-ctp.com’s FeedSync implementation is more tolerant of arbitrary data than user-ctp.windows.net. By using this back door, the Live Framework Client is able to preserve our original <published> date.
If you want to learn more about Windows Live Core, you can use Fiddler to inspect the Live Framework Client’s communication. You can also use Reflector to check out the Microsoft.Live.Core.Resources namespace in Microsoft.MeshOperatingEnvironment.Runtime.Client.WlcProxies.dll located in C:\Users\[username]\AppData\Local\Microsoft\Live Framework Client\Bin\Moe2\.
DataFeed vs. DataEntries feed
So far I have focused on the issues when importing individual Atom entries within a feed. There are also issues when importing metadata for the feed itself. But first it is useful to discuss the differences between a DataFeed and its DataEntries feed.
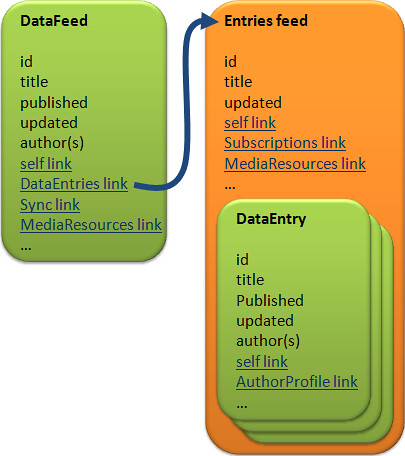
In the picture above, green=entry and orange=feed. The most obvious thing to note here is that DataFeed is an entry that links to an Entries feed containing multiple DataEntries.
The Entries feed’s <title> is read-only and is always “DataEntries”. <id> and the rest of the elements listed above are auto-generated by the Live Operating Environment. The DataEntries feed isn’t extensible, so you can’t add links to things such as the original feed’s self link or alternate link.
This means that if you want to preserve any feed metadata from your original feed, you must store it somewhere else. The DataFeed entry is a likely candidate.
You can store the original feed’s title in the DataFeed’s title. You can also add any links from the original feed that don’t conflict with LOE-managed links such as self link. If you need to store the original feed’s self link, you can do this by renaming its rel and title attributes.
It should now be quite clear that importing external feeds is like putting a square peg in a round hole. Even if you find a way to do it, you won’t be able to take existing Twitter clients and easily tweak them to use Live Framework’s imported Twitter feeds.
Other considerations for apps
I noticed a few other interesting things as I was exploring. The local LOE correctly lists imported tweets in reverse chronological order (the order in which they were imported). When these tweets are synchronized with the cloud LOE, they are listed in chronological order (the exact opposite of the local LOE).
You can use Resource Scripts to import external feeds, as I demonstrated in the code sample for this post. With the new Loop statement, this becomes even easier. However, Resource Scripts can only read external feeds when the script is executed locally, not in the cloud.
Whether you’re importing one item at a time or using Resource Scripts for bulk imports, it is clearly preferable to import using the local LOE. But what if you want to use delegated auth to import data using a 3rd-party website? Unless you figure out how to hack WLC (which I doubt supports delegated auth), you’re out of luck when it comes to the <published> date because you don’t have a local LOE.
Hope for the future: Federated Storage
I don’t know much about Federated Storage Services since I didn’t have access to the pre-CTP release that supposedly exposed them, but I believe the idea is to allow third parties to create proxies to their services, similar to how Contacts and Profiles from Hotmail’s Address Book Clearing House (ABCH) are currently exposed. You can see hints of Federated Services if you paste the following link into the Live Framework Resource Browser:
https://user-ctp.windows.net/V0.1/Mesh/SomeRandomUri
I would imagine that this would provide a better option for “importing” 3rd-party data into the mesh. You would probably have much greater control over the URIs, titles, and more. Furthermore, this data wouldn’t need to be stored in Microsoft’s datacenters. This is especially important if you want to “import” feeds with sizeable enclosures such as pictures and video.
One possible downside of Federated Storage is that I imagine you won’t be able to arbitrarily annotate data in external feeds, reducing their potential in data mashup scenarios. This limitation already manifests itself in the inability to persist Delete triggers for Contacts and Profiles.
Another request for “Yahoo Pipes for AtomPub”
At the end of this blog post, I proposed using Live Framework to enable something like Yahoo Pipes for AtomPub. This would enable you to import and mash up arbitrary feeds, perhaps supplemented by a visual Resource Script designer. I believe support for raw Atom feeds is crucial for this scenario. Support for raw RSS feeds may also be desirable.
Feature request
If you want to easily build Live Framework apps that import feeds from external sources, please vote on this feature request on Connect. Thanks!